All in One View
Content from Introduction
Last updated on 2025-07-17 | Edit this page
Overview
Questions
- Why do we test software?
Objectives
- Understand what is testing
- Understand the goals of testing
What is testing?
Software testing is the process of executing the software to discover any discrepancies between the expected behavior and the actual behavior of the software. Thus, the focus of testing is to execute the software with a set of “good” inputs and verify the produced outputs match some expected outputs.
Anatomy of a test
A software test typically involves the following activities.
Designing test inputs: It is not practical to test software with all possible inputs. Therefore we need to select a subset of inputs that are likely to detect bugs and would help to increase our confidence in the program. One approach is to randomly select inputs from the input space. While this can be an effective method, it has the tendency to miss corner cases where most mistakes are made. Therefore we will be discussing several approaches used for developing test inputs.
Test execution: tests need should be executed multiple times when code is changed some way, when implementing new features or when fixing bugs. Thus execution of tests should be automated as much as possible with the help of test frameworks (i.e. test tools) and CI/CD infrastructure.
Checking the test outputs: this is done by comparing the output of test cases with the expected output of the software and should be automated as well.
Verification vs. validation
Notice that we did not define testing as confirming that the software is correct because testing alone cannot prove that software is correct. Even if you could execute the software with all possible inputs, all that would do is confirm that the outputs produced agree with what the tests understand as the expected behavior, i.e. with the specifications.
Software engineering lingo captures this distinction with the (non-interchangeable) terms “verification” and “validation”:
Verification : does the software do what the specification says it should do? In other words, does the output match expectations?
Validation : are those even the right specs in the first place? In other words, do our expectations align with reality or scientific ground truth? Or in yet other words, is verified code correct?
On its own, testing is about verification. Validation requires extra steps: attempts at replication, real-world data/experimentation, scientific debate and arrival at consensus, etc.
Of course, having a robust (and ideally automated) verification system in place is what makes validation possible. That’s why systematic testing is the most widely used technique to assure software quality, to uncover errors, and to make software more reliable, stable, and usable.
Why (else) do we test?
When asked this question, most of us instinctively answer “to make sure the code is correct”. We’ve just seen that while testing is an essential component in validation, it doesn’t really accomplish this on its own. So why else should we test?
- Uncover bugs
- Document bugs
- Document the specifications, more broadly (and more specifically)
- Detect regressions
- Guide the software design
- Circumscribe and focus your coding (avoiding “feature creep”)
When to run tests?
The earlier a bug is detected, the less costly it is to fix. For example, a bug detected and fixed during coding is 50 times cheaper than detecting and fixing it after the software is deployed. Imagine the cost of publishing code with a bug! However, executing tests as soon as possible is also immediately beneficial. When you discover a bug after just having changed 3 lines of code, you know exactly where to look for a mistake. We will discuss automated methods to run whole suites of quick tests on a very high cadence.
When to write tests?
Most of us are in the habit of writing tests after the code is written. This seems like a no-brainer: after all, how can you test something that doesn’t exist yet? But this thinking is an artifact of believing that the primary (or only) purpose of testing is to “make sure the code is correct”.
One of the main takeaways of today’s lesson — and also the one that you will most resist — is that writing and running a test for code that doesn’t yet exist is precisely what you ought to be doing. This approach is called Test Driven Development (TDD) and we will discuss it a little later.
- Testing improves confidence about your code. It doesn’t prove that code is correct.
- Testing is a vehicle for both software design and software documentation.
- Creating and executing tests should not be an afterthought. It should be an activity that goes hand-in-hand with code development.
- Tests are themselves code. Thus, test code should follow the same overarching design principles as functional code (e.g. DRY, modular, reusable, commented, etc).
Content from Working with Legacy Code
Last updated on 2025-05-21 | Edit this page
Overview
Questions
- What is legacy code?
- Why should you test legacy code before changing it?
Objectives
- Understand the sample legacy code
- Set up an end-to-end test
- Use TDD to begin refactoring
Meet the legacy code project
Imagine you are joining a new lab and have inherited a script from
another grad student or published paper. It takes in a file with
coordinates of rectangles and produces a matrix where the value at index
i,j == 1 if rectangle i overlaps with
rectangle j, and 0 otherwise. Here is the
starting script
PYTHON
import sys
# read input file
infile = open(sys.argv[1], 'r')
outfile = open(sys.argv[2], 'w')
# build rectangle struct
dict = {}
for line in infile:
name, *coords = line.split()
dict[name] = [int(c) for c in coords]
for red_name, red_coords in dict.items():
for blue_name, blue_coords in dict.items():
# check if rects overlap
result = '1'
red_lo_x, red_lo_y, red_hi_x, red_hi_y = red_coords
blue_lo_x, blue_lo_y, blue_hi_x, blue_hi_y = blue_coords
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_x) or (red_hi_y <= blue_lo_y):
result = '0'
outfile.write(result + '\t')
outfile.write('\n')
infile.close()
outfile.close()Critique the published version
The code above is certainly not perfect. Name 3 issues with the code
and (to be nice) 1 good thing.
Consider if the problems will affect testing or can be addressed with
testing.
Starting with good things: 1. Variable names are fairly clear and properly formatted (snake case) 2. Comments are used properly 3. Runs without errors 4. Dependencies are handled (no dependencies)
And some of the issues: 1. Unable to import as a module 2. No
encoding specified on open 3. Redundant execution in main
loop 4. Several assumptions made without checking or asserting
correctness (hi vs. low, int coords) 5. Shadowing dict
keywords 6. Trailing tab on the end of each output line 7. Not using
context managers for file io
Now your advisor wants you to take this code, make it run twice as
fast and instead of just saying if there is overlap, output the percent
the two areas overlap! You think you need to introduce a
Rectangle object, but how can you make changes without
adding to this pile of code?
A simple end-to-end test
The first step to making legacy code into tested code is to add a test.
Legacy code has many negative connotations. Here we are using it as defined by Micheal Feathers in Working Effectively with Legacy Code. “To me, legacy code is simply code without tests.” All the other bad features of legacy code stem from a lack of testing.
Often the best test to write first is an end-to-end or integration test. These kinds of tests exercise an entire codebase with some “representative” input and ensure the correct output is produced. You probably use a test like this, even if you don’t have it automated or formalized. End-to-end tests ensure the code is working in its entirety and giving the same output. They are often not ideal since with non-trivial systems they can take significant time or resources to run and verify. It is also difficult to test many corner cases without testing smaller parts of a codebase.
Like all tests, passing does not verify correctness just that the
tests are not failing. Still, it is reassuring that some larger
refactoring isn’t breaking published code! Let’s start with this simple
input file (the columns are name x1 y1 x2 y2):
Clearly rectangles a and b overlap while c is far away. As output, we expect the following matrix:
Critique the sample input
What are some issues with the sample input? Is the result still useful?
The input doesn’t test rectangles where x != y or really
exercise the code with more interesting cases (overlap at a point, a
line, overlap exactly, etc).
The result can still be useful if it fails. Knowing something that was working has stopped working can notify you an error is present. However, having this test pass doesn’t make your code correct!
Given the input.txt and output.txt files,
how can we test the function? You may be used to doing this manually,
with the following commands:
BASH
# run the command
python overlap_v0.py input.txt new_output.txt
# view the result
cat new_output.txt
# compare the outputs
cmp output.txt new_output.txtOn every change to the file, you can press the up arrow or
Ctrl+p to recall a command and rerun it. Bonus points if
you are using multiple terminal sessions or a multiplexer. A better
setup is to formalize this test with a script you can repeatedly run.
Tools like entr or your
text editor can automatically run the test when your files change. Here
is a simple end-to-end test of the initial script:
BASH
#!/bin/bash
# run the command
python overlap_v0.py input.txt new_output.txt
# compare the outputs
cmp output.txt new_output.txt && echo 'passes'When cmp is successful (no difference between files)
passes will be echoed to the terminal. When it fails the
byte and line number that differs will be printed. This script can be
run with CI and should act as the final step to ensure your outputs are
as expected. Think of tests like a funnel: you want to run quick tests
frequently to catch most bugs early, on every file write. Slower tests
can run prior to a git commit to catch the bugs that escaped the first
round. Finally, the slowest, most thorough tests run via CI/CD on a PR
and should catch a minority of bugs. We will run our end to end test
after making major changes.
You can also add more test files to this script but we want to move to a better testing framework ASAP!
- Legacy code is code without tests. It’s extremely challenging to change code that doesn’t have tests.
- At the very least you should have an end-to-end test when starting to change code.
- Try to add tests before making changes, work in small steps.
- Having tests pass doesn’t mean your code is correct.
Content from Test framework
Last updated on 2025-07-17 | Edit this page
Overview
Questions
- What is a test framework?
- How to write test cases using a test frmework?
Objectives
- Start running tests with pytest.
pytest: A test framework
While it is not practical to test a program with all possible inputs we should execute multiple tests that exercise different aspects of the program. Thus, to ease this process we use test frameworks. It is simply a software tool or library that provides a structured and organized environment for designing, writing, and executing tests. Here we will be using pytest, which is a widely used testing framework for Python.
Follow the instructions here to install pytest if you haven’t done so already. We will be using pytest in as our test framework.
Test already!
Now let’s make sure pytest is set up and ready to test.
In a larger package the structure should follow what you’ve already been taught, with source code and tests in different directories. Here we will stick in the same folder for simplicity.
Pytest looks for files that start with test_ and runs
any functions in those files that start with test_. In
contrast to unittest or other x-unit style frameworks,
pytest has one test statement, assert which works exactly
like in normal python code. Here are some pointless tests:
PYTHON
# test_nothing.py
def test_math():
assert 2 + 2 == 4
def test_failure():
assert 0 # zero evaluates to falseIn the same directory as your test files, run
pytest:
BASH
$ pytest
========================================== test session starts ==========================================
platform linux -- Python 3.9.16, pytest-7.3.1, pluggy-1.0.0
rootdir: ~/projects/testing-lesson/files
plugins: anyio-3.6.2
collected 2 items
test_nothing.py .F [100%]
=============================================== FAILURES ================================================
_____________________________________________ test_failure ______________________________________________
def test_failure():
> assert 0 # zero evaluates to false
E assert 0
test_nothing.py:5: AssertionError
======================================== short test summary info ========================================
FAILED test_nothing.py::test_failure - assert 0
====================================== 1 failed, 1 passed in 0.06s ======================================Note that two tests were found. Passing tests are marked with a green
. while failures are F and exceptions are
E.
Writing actual test cases
Let’s understand writing a test case using the following function
that is supposed to compute x + 1 given x.
Note the very obvious bug.
A typical test case consits of the following components: 1. A test input. 2. A call to the function under test with the test input. 3. A statement to compare the output with the expected output.
Following is a simple test case written to test func(x).
Note that we have given a descriptive name to show what function is
tested and and with what type of input. This is a good practice to
increase the readability of tests. You shouldn’t have to explicitly call
the test functions, so don’t worry if the names are longer than you
would normally use. The test input here is 3 and the expected output is
4. The assert statement checks the equality of the two.
PYTHON
#test_sample_calc.py
import sample_calc as sc
def test_func_for_positive_int():
input_value = 3 # 1. test input
func_output = sc.func(input_value) # 2. call function
assert func_output == 4 # 3. compare output with expectedWhen the test is executed it is going to fail due to the bug in
func.
BASH
$ pytest test_sample_calc.py
============================= test session starts ==============================
platform darwin -- Python 3.9.12, pytest-7.1.1, pluggy-1.0.0
rootdir: /Volumes/Data/Work/research/INTERSECT2023/TestingLesson
plugins: anyio-3.5.0
collected 1 item
test_sample_calc.py F [100%]
=================================== FAILURES ===================================
_________________________________ test_answer __________________________________
def test_answer():
> assert sc.func(3) == 4
E assert 2 == 4
E + where 2 = <function func at 0x7fe290e39160>(3)
E + where <function func at 0x7fe290e39160> = sc.func
test_sample_calc.py:4: AssertionError
=========================== short test summary info ============================
FAILED test_sample_calc.py::test_answer - assert 2 == 4
============================== 1 failed in 0.10s ===============================Improve the code
Modify func and test_sample_calc.py: 1. Fix
the bug in the code. 2. Add two tests test with a negative number and
zero.
- Clearly
funcshould returnx + 1instead ofx - 1 - Here are some additional assert statements to test more values.
PYTHON
assert sc.func(0) == 1
assert sc.func(-1) == 0
assert sc.func(-3) == -2
assert sc.func(10) == 11How you organize those calls is a matter of style. You could have one
test_ function for each or group them into a single
test_func_hard_inputs. Pytest code is just python code, so
you could set up a loop or use the pytest.parameterize
decorator to call the same code with different inputs.
We will cover more features of pytest as we need them. Now that we know how to use the pytest framework, we can use it with our legacy code base!
What is code (test) coverage
The term code coverage or coverage is used to refer to the code constructs such as statements and branches executed by your test cases.
Note: It is not recommended to create test cases to simply to cover the code. This can lead to creating useless test cases and a false sense of security. Rather, coverage should be used to learn about which parts of the code are not executed by a test case and use that information to augment test cases to check the respective functionality of the code. In open source projects, assuring high coverage can force contributors to test their new code.
We will be using Coverage.py to calculate the coverage of the test cases that we computed above. Follow the instructions here to install Coverage.py.
Now let’s use Coverage.py to check the coverage of the tests we
created for func(x), To run your tests using pytest under
coverage you need to use the coverage run command:
BASH
$ coverage run -m pytest test_sample_calc.py
============================= test session starts ==============================
platform darwin -- Python 3.9.12, pytest-7.1.1, pluggy-1.0.0
rootdir: /Volumes/Data/Work/research/INTERSECT2023/TestingLesson
plugins: anyio-3.5.0
collected 1 item
test_sample_calc.py F [100%]
=================================== FAILURES ===================================
_________________________________ test_answer __________________________________
def test_answer():
> assert sc.func(3) == 4
E assert 2 == 4
E + where 2 = <function func at 0x7fab8ca2be50>(3)
E + where <function func at 0x7fab8ca2be50> = sc.func
test_sample_calc.py:4: AssertionError
=========================== short test summary info ============================
FAILED test_sample_calc.py::test_answer - assert 2 == 4
============================== 1 failed in 0.31s ===============================To get a report of the coverage use the command
coverage report:
BASH
$ coverage report
Name Stmts Miss Cover
-----------------------------------------
sample_calc.py 2 0 100%
test_sample_calc.py 3 0 100%
-----------------------------------------
TOTAL 5 0 100%Note the statement coverage of sample_calc.py which is 100% right
now. We can also specifically check for the executed branches using the
--branch flag with the coverage run command.
You can use the --module flag with the
coverage report command to see which statements are missed
with the test cases if there is any and update the test cases
accordingly.
- A test framework simplifies adding tests to your project.
- Choose a framework that doesn’t get in your way and makes testing fun.
- Coverage tools are useful to identify which parts of the code are executed with tests
Content from Test Driven Development
Last updated on 2025-07-17 | Edit this page
Overview
Questions
- Why should you write tests first?
- What are the 3 phases of TDD?
Objectives
- Start running tests with pytest.
- Replace the end-to-end test with a pytest version.
Test Driven Development
Test Driven Development (or TDD) has a history in agile development but put simply you’re going to write tests before you write code (or nearly the same time). This is in contrast to the historical “waterfall” development cycle where tests were developed after code was written e.g. on a separate day or business quarter.
You don’t have to be a TDD purist as long as your code ends up having tests. Some say TDD makes code less buggy, though that may not be strictly true. Still, TDD provides at least three major benefits:
It greatly informs the design, making for more maintainable, legible and generally pretty code. Writing code is much faster since you’ve already made the difficult decisions about its interface.
It ensures that tests will exist in the first place (b/c you are writing them first). Remember, everyone dislikes writing tests, so you should hack yourself to get them done.
It makes writing tests A LOT more fun and enjoyable. That’s because writing tests when there’s no code yet is a huge puzzle that feels more like problem-solving (which is what programmers like) than clerical work or bookkeeping (which programmers generally despise).
Often times when you write tests with existing code, you anchor your expectations based on what the code does, instead of brain storming on what a user could do to break your system.
Red, green, refactor
The basic cycle of work with TDD is called red, green, refactor:
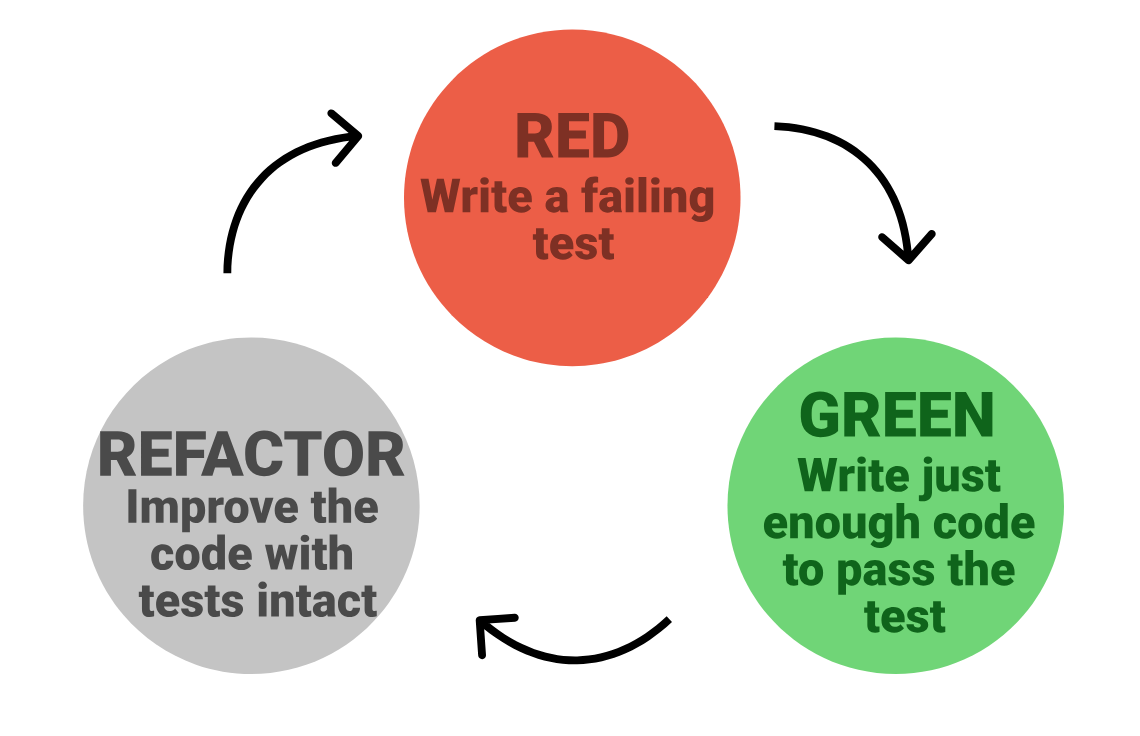
Start by writing a failing test. This is the red phase since your test runner will show a failure, usually with a red color. Only when you having a failing test can you add a feature.
Add only as much code to make the test pass (green). You want to work on the code base only until your tests are passing, then stop! This is often difficult if you are struck by inspiration but try to slow down and add a note to come back to. Maybe you identified the next test to write!
Look over your code and tests and see if anything should be refactored. Refactoring is the process of restructuring or improving the internal structure of existing source code without changing its external behavior. It can involve modifications to the code to make it more readable, maintainable, efficient, and adhering to best coding practices. At this point your test suite is passing and you can really get creative. If a change causes something to break you can easily undo it and get back to safety. Also, having this as a separate step allows you to focus on testing and writing code in the other phases. Remember, tests are code too and benefit from the same design considerations.
You will be repeating these red, green, refactor steps multiple times until you are done with developing code. Therefore we need to automate the execution of tests using testing frameworks. Here we will be using pytest, which is a widely used testing framework for Python. It provides a comprehensive and flexible set of tools and features for writing and executing tests.
Importing overlap.py, red-green-refactor
Getting back to the overlap script, let’s start with a failing test.
Red
You may be surprised how easy it is to fail:
PYTHON
# test_overlap.py
import overlap_v0 as overlap # change version as needed
def test_import():
passWhen you run pytest, you get an error due to the line opening
sys.argv[1] when we aren’t providing an input file. Note
how brittle the original design is, if we wanted to use part of the file
somewhere else we aren’t able to since the file expects to be called as
the main method. If you wanted to change command line parsers or use
some part in a notebook, you would quickly run into problems.
Green
Maybe you are thinking about how to pull file IO out of this function, but to start we do the least amount possible to pass our test (which is really just importing):
PYTHON
# overlap.py
import sys
def main():
# read input file
infile = open(sys.argv[1], 'r')
outfile = open(sys.argv[2], 'w')
# ...
if __name__ == "__main__":
main()Now execute test_overlap.py with pytest:
BASH
$ pytest test_overlap.py
========================================== test session starts ===========================================
platform linux -- Python 3.9.16, pytest-7.3.1, pluggy-1.0.0
rootdir: ~/projects/testing-lesson/files
plugins: anyio-3.6.2
collected 1 item
test_overlap.py . [100%]
=========================================== 1 passed in 0.01s ============================================You can be extra thorough and see if end-to-end.sh still
passes.
Refactor
At this point, our pytest function is just making sure we can import
the code. But our end-to-end test makes sure the entire function is
working as expected (albeit for a small, simple input). How about we
move the file IO into the main function?
Refactor
Change file IO to occur in the main function. Your new
main function should look like
def main(infile, outfile).
PYTHON
def main(infile, outfile):
...
if __name__ == "__main__":
with open(sys.argv[1], encoding='utf-8') as infile, \
open(sys.argv[2], 'w', encoding='utf-8') as outfile:
main(infile, outfile)That addresses the context manager and encoding of files. Continue to run your tests to see your changes are ok!
After refactoring save the code as overlap_v1.py.
End-to-end testing with pytest
We have a lot to address, but it would be nice to integrate our end
to end test with pytest so we can just run one command. The problem is
our main function deals with files. Reading and writing to
a file system can be several orders of magnitude slower than working in
main memory. We want our tests to be fast so we can run them all the
time. The nice thing about python’s duck typing is the infile and
outfile variables don’t have to be open files on disk, they can be in
memory files. In python, this is accomplished with a StringIO object
from the io library.
A StringIO object acts just like an open file. You can read and
iterate from it and you can write to it just like an opened text file.
When you want to read the contents, use the function
getvalue to get a string representation.
Red
Let’s write a test that will pass in two StringIO objects, one with the file to read and one for the output.
PYTHON
# test_overlap.py
import overlap_v1 as overlap
from io import StringIO
def test_end_to_end():
## ARRANGE
# initialize a StringIO with a string to read from
infile = StringIO(
'a 0 0 2 2\n'
'b 1 1 3 3\n'
'c 10 10 11 11'
)
# this holds our output
outfile = StringIO()
## ACT
# call the function
overlap.main(infile, outfile)
## ASSERT
output = outfile.getvalue().split('\n')
assert output[0].split() == '1 1 0'.split()
assert output[1].split() == '1 1 0'.split()
assert output[2].split() == '0 0 1'.split()Since this is the first non-trivial test, let’s spend a moment going
over it. As before, we import our module and make our test function
start with test_. The actual name of the function is for
your benefit only so don’t be worried if it is “too long”. You won’t
have to type it so be descriptive! Next we have the three steps in all
tests:
Arrange-Act-Assert (aka Given-When-Then)
Arrange: Set up the state of the program in a particular way to test the feature you want. Consider edge cases, mocking databases or files, building helper objects, etc.
Act: Call the code you want to test
Assert: Confirm the observable outputs are what you expect (i.e. compare the output with the expected output). Notice that the outputs here read like the actual output file.
Again, pytest uses plain assert statements to test
results.
But we have a problem: our test passes! This is partially because we are replacing an existing test, but it reveals a broader concern: how can you be sure you are testing what you think you are testing? Maybe you are importing a different version of code, maybe pytest isn’t finding your test, etc. Often a test that passes when it should fail is more diagnostically worrisome than a test that fails when it should be passing.
Notice the splits in the assert section, they normalize
the output so any whitespace will be accepted. Let’s replace those with
explicit white space (tabs) and see if we can go red:
Since split('\n') strips off the newline at the end of
each line. Now we fail (yay!) and it’s due to something we have wanted
to change anyways. The pytest output says
that is, we have an extra tab at the end of our lines.
Green
Fix the code
Change the overlap file to make the above test pass. Hint, change when and where you write a tab to the file.
There are a few options here. I’m opting for building a list and
using join for the heavy lifting.
PYTHON
for red_name, red_coords in dict.items():
output_line = []
for blue_name, blue_coords in dict.items():
# check if rects overlap
result = '1'
red_lo_x, red_lo_y, red_hi_x, red_hi_y = red_coords
blue_lo_x, blue_lo_y, blue_hi_x, blue_hi_y = blue_coords
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_x) or (red_hi_y <= blue_lo_y):
result = '0'
output_line.append(result)
outfile.write('\t'.join(output_line) + '\n')Once you get the test passing you will notice that the
end-to-end.sh will no longer pass! One of the reasons to
test code is to find (and prevent) bugs. When you work on legacy code,
sometimes you will find bugs in published code and the questions can get
more problematic. Is the change something that will alter published
results? Was the previous version wrong or just not what you prefer? You
may decide to keep a bug if it was a valid answer! In this case we will
keep the change and not have a tab followed by a newline.
Refactor
Let’s focus this round of refactoring on our test code and introduce some nice pytest features. First, it seems like we will want to use our simple input file in other tests. Instead of copying and pasting it around, let’s extract it as a fixture.
pytest Fixtures
Pytest fixtures can do a lot, but for now we just need a StringIO object built for some tests:
PYTHON
# test_overlap.py
import overlap_v1 as overlap
from io import StringIO
import pytest
@pytest.fixture()
def simple_input():
return StringIO(
'a 0 0 2 2\n'
'b 1 1 3 3\n'
'c 10 10 11 11'
)
def test_end_to_end(simple_input):
# initialize a StringIO with a string to read from
infile = simple_input
...We start by importing pytest so we can use the
@pytest.fixture() decorator. This decorates a function and
makes its return value available to any function that uses it as an
input argument. Next we can replace our infile definition
by assigning it to simple_input in
test_end_to_end.
For this code, the end-to-end test runs quickly, but what if it took
several minutes? Ideally we could run our fast tests all the time and
occasionally run everything, including slow tests. The simplest way to
achieve this with pytest is to mark the function as slow and invoke
pytest with pytest -m "not slow":
BASH
pytest -m "not slow" test_overlap.py
========================================== test session starts ===========================================
platform linux -- Python 3.9.16, pytest-7.3.1, pluggy-1.0.0
rootdir: ~/projects/testing-lesson/files
plugins: anyio-3.6.2
collected 1 item / 1 deselected / 0 selectedNote that the one test was deselected and not run. You can (and should) formalize this mark as described in the warning that will pop up!
- TDD cycles between the phases red, green, and refactor
- TDD cycles should be fast, run tests on every write
- Writing tests first ensures you have tests and that they are working
- Making code testable forces better style
- It is much faster to work with code under test
Content from Refactoring for Testing
Last updated on 2025-07-18 | Edit this page
Overview
Questions
- Why are long methods hard to test?
Objectives
- Learn some key refactoring methods to change code safely.
- Modify the overlap script to support a Rectangle object.
Monolithic main functions
One of the smelliest code smells that new developers make is having a
single main() function that spans several hundred
(thousand?) lines. Even if the code is perfect, long functions and
methods are an anti-pattern because they require a reader of the code to
have exceptionally good working memory to understand the function or
method. It also becomes impossible to reuse part of the code
elsewhere.
Consider the following two sections of code:
PYTHON
if user is not None and user in database and database[user]['type'] == 'admin':
# do admin work
#### vs ####
def user_is_admin(user, database):
return user is not None and user in database and database[user]['type'] == 'admin'
if user_is_admin(user, database):
# do admin workThe second version puts less stress on the reader because when they
see the function called user_is_admin they can treat it
like a black box until they are interested in the internals. But we are
here to talk about testing!
Consider writing a test for the first version, where all the logic of what makes a user an admin is in the if statement. To even get to this line of code you will have to set up your system and possibly mock or replace other function calls.
But as a separate function, your test becomes a unit test, exercising a small piece of code. Here is a possible pytest:
PYTHON
def test_user_is_admin():
user = None
database = {}
assert user_is_admin(user, database) is False, "None user is not an admin"
user = "Jim"
database = {}
assert user_is_admin(user, database) is False, "User not in database"
database = {"Jim": {"type": "regular"}}
assert user_is_admin(user, database) is False, "User is not an admin"
database = {"Jim": {"type": "admin"}}
assert user_is_admin(user, database) is True, "User is an admin"A surprising benefit of TDD and testing is that having to write code with tests makes your code better! It’s just too hard to write tests for bad code; if you have to write a test then it’s easier to just write better code.
Safe Refactoring and TDD
Reading in Rectangles
Now back to our overlap code. You have inherited a monolithic main
method, how do you go about breaking it up? Some IDEs have functions for
extracting a method or attribute but we are following TDD and need to
write a failing test first. Let’s start with the first portion of our
existing main method, reading in the dict:
Red
PYTHON
# overlap.py
def main(infile, outfile):
# build rectangle struct
dict = {}
for line in infile:
name, *coords = line.split()
dict[name] = [int(c) for c in coords]
...We have a design decision to make. Should we extract the entire for loop or just the inside? The current code works with an open file, but any iterable could do (say a list of strings). Your decision should be informed by what is useful and what is easy to test. Having a function to convert a string to a rectangle could be handy, but for now we will take the entire for loop.
PYTHON
# test_overlap.py
def test_read_rectangles_simple(simple_input):
rectangles = overlap.read_rectangles(simple_input)
assert rectangles == {
'a': [0, 0, 2, 2],
'b': [1, 1, 3, 3],
'c': [10, 10, 11, 11],
}Which fails because we don’t have a method named
read_rectangles. Note that we have already decided on a
name for the function, its arguments and return values without touching
our source code.
Green
Now we can pull out the function and replace that for loop with a function call.
Fix the code
Change the overlap file to make the above test pass.
PYTHON
def main(infile, outfile):
dict = read_rectangles(infile)
...
def read_rectangles(infile):
result = {}
for line in infile:
name, *coords = line.split()
result[name] = [int(c) for c in coords]
return resultWhen you start refactoring like this go slow and in parts. Make the
function first and when the test_read_rectangles passes
replace the code in the main method. Your end to end test should still
pass and tell you if something is wrong. Note we can remove the comment
because the function name is self documenting.
Refactor
With read rectangles pulled out, let’s rename our dict
to rectangles. Since the argument to our function can be any iterable of
strings, we can also rename it to rectangles and add a type
annotation to show what we expect as input. Now is also the time to add
a doc string. Make changes step-wise and run your tests frequently.
PYTHON
from collections.abc import Iterable
def main(infile, outfile):
rectangles = read_rectangles(infile)
...
def read_rectangles(rectangles: Iterable[str]) -> dict[str, list[float]]:
result = {}
for rectangle in rectangles:
name, *coords = rectangle.split()
result[name] = [int(c) for c in coords]
return resultNote our return value is a list of floats, ints are implied by that and we may want to support floats later (hint, we do!).
Test like an adversary
With a small, testable method in place, we can start adding features and get creative. Often you will take the mindset of an adversary of a codebase. This is generally easier with someone else’s code because you can think “I bet they didn’t think of this” instead of “why didn’t I think of this”, but being self-deprecating gets easier with practice.
Think of all the ways the overlap code could break, all the things that aren’t tested, and how you would expect them to be handled. Remember users aren’t perfect so expect non-optimal inputs. It’s better to fail early (and descriptively) than several lines or modules away.
Red-Green-Refactor the
read_rectangles
Pick one of the following and work through a red-green-refactor cycle to address it. Work on more as time permits. Remember to keep each phase short and run pytest often. Stop adding code once a test starts passing. - How to handle empty input? - Non-numeric X and Y coordinates? - X and Y coordinates that are floats? - X and Y coordinates not equal? (how are we not testing this!) - X and Y coordinates are not in increasing order? - Incorrect number of coordinates supplied? - Any others you can think of?
Often there isn’t one right answer. When the user gives an empty
file, should that be an empty result or throw an error? The answer may
not matter, but formalizing it as a test forces you to answer and
document such questions. Look up pytest.raises for how to
test if an exception is thrown.
Here is one set of tests and passing code. You may have chosen different behavior for some changes.
PYTHON
# test_overlap.py
def test_read_rectangles_empty_input_empty_output():
rectangles = overlap.read_rectangles([])
assert rectangles == {}
def test_read_rectangles_non_numeric_coord_raise_error():
with pytest.raises(ValueError) as error:
overlap.read_rectangles(['a a a a a'])
assert "Non numeric value provided as input for 'a a a a a'" in str(error)
def test_read_rectangles_accepts_floats():
lines = ['a 0.3 0.3 1.0 1.0']
rectangles = overlap.read_rectangles(lines)
coords = rectangles['a']
# Note that 0.3 != 0.1 + 0.2 due to floating point error, use pytest.approx
assert coords[0] == pytest.approx(0.1 + 0.2)
assert coords[1] == 0.3
assert coords[2] == 1.0
assert coords[3] == 1.0
def test_read_rectangles_not_equal_coords():
lines = ['a 1 2 3 4']
rectangles = overlap.read_rectangles(lines)
assert rectangles == {'a': [1, 2, 3, 4]}
def test_read_rectangles_fix_order_of_coords():
lines = ['a 3 4 1 2']
rectangles = overlap.read_rectangles(lines)
assert rectangles == {'a': [1, 2, 3, 4]}
def test_read_rectangles_incorrect_number_of_coords_raise_error():
with pytest.raises(ValueError) as error:
overlap.read_rectangles(['a 1'])
assert "Incorrect number of coordinates for 'a 1'" in str(error)
with pytest.raises(ValueError) as error:
overlap.read_rectangles(['a'])
assert "Incorrect number of coordinates for 'a'" in str(error)PYTHON
# overlap.py
def read_rectangles(rectangles: Iterable[str]) -> dict[str, list[float]]:
result = {}
for rectangle in rectangles:
name, *coords = rectangle.split()
try:
value = [float(c) for c in coords]
except ValueError:
raise ValueError(f"Non numeric value provided as input for '{rectangle}'")
if len(value) != 4:
raise ValueError(f"Incorrect number of coordinates for '{rectangle}'")
# make sure x1 <= x2, value = [x1, y1, x2, y2]
value[0], value[2] = min(value[0], value[2]), max(value[0], value[2])
value[1], value[3] = min(value[1], value[3]), max(value[1], value[3])
result[name] = value
return resultNotice how the test code is much longer than the source code, this is typical for well-tested code.
A good question is, do we need to update our end-to-end test to cover
all these pathological cases? The answer is no (for most). We already
know our read_rectangles will handle the incorrect number
of coordinates by throwing an informative error so it would be redundant
to see if the main function has the same behavior. However,
it would be useful to document what happens if an empty input file is
supplied. Maybe you want read_rectangles to return an empty
dict but the main method should warn the user or fail.
The decision not to test something in multiple places is more important than being efficient with our time writing tests. Say we want to change the message printed for one of the improper input cases. If the same function is tested multiple places we need to update multiple tests that are effectively covering the same feature. Remember that tests are code and should be kept DRY. Tests that are hard to change don’t get run and code eventually degrades back to a legacy version.
Testing how we test for overlap
We have arrived to the largest needed refactoring, the overlap code. This is the internals of the nested for loop.
PYTHON
...
for blue_name, blue_coords in rectangles.items():
# check if rects overlap
result = '1'
red_lo_x, red_lo_y, red_hi_x, red_hi_y = red_coords
blue_lo_x, blue_lo_y, blue_hi_x, blue_hi_y = blue_coords
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_x) or (red_hi_y <= blue_lo_y):
result = '0'
...Like before, we want to write a failing test first and extract this method. When that is in place we can start getting creative to test more interesting cases. Finally, to support our original goal (reporting the percent overlap) we will change our return type to another rectangle.
For testing, I’m using the simple input, when parsed from
read_rectangles. Notice that if we had used
read_rectangles to do the parsing we would add a dependency
between that function and this one. If we change (break)
read_rectangles this would break too even though nothing is
wrong with rects_overlap. However, uncoupling them
completely doesn’t capture how they interact in code. Consider the
drawbacks before deciding what to use.
PYTHON
# test_overlap.py
def test_rects_overlap():
rectangles = {
'a': [0, 0, 2, 2],
'b': [1, 1, 3, 3],
'c': [10, 10, 11, 11],
}
assert overlap.rects_overlap(rectangles['a'], rectangles['a']) is True
assert overlap.rects_overlap(rectangles['a'], rectangles['b']) is True
assert overlap.rects_overlap(rectangles['b'], rectangles['a']) is True
assert overlap.rects_overlap(rectangles['a'], rectangles['c']) is FalsePYTHON
# overlap.py
def main(infile, outfile):
rectangles = read_rectangles(infile)
for red_name, red_coords in rectangles.items():
output_line = []
for blue_name, blue_coords in rectangles.items():
result = '1' if rects_overlap(red_coords, blue_coords) else '0'
output_line.append(result)
outfile.write('\t'.join(output_line) + '\n')
...
def rects_overlap(red, blue) -> bool:
red_lo_x, red_lo_y, red_hi_x, red_hi_y = red
blue_lo_x, blue_lo_y, blue_hi_x, blue_hi_y = blue
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_x) or (red_hi_y <= blue_lo_y):
return False
return TrueNow we can really put the function through it’s paces. Here are some rectangles to guide your testing:
┌───┐ ┌──┬──┐ ┌──────┐ ┌─┐
│ ┌┼─┐ │ │ │ │ ┌──┐ │ └─┼─┐
└──┼┘ │ └──┴──┘ └─┼──┼─┘ └─┘
└──┘ └──┘ For each, consider swapping the red and blue labels and rotating 90 degrees.
Helpful math fact: Rotating a coordinate 90 degrees clockwise is simply swapping x and y and then negating the new y value.
Note that if you thought the rotation function would be useful elsewhere, you could add it to your script, but for now we will keep it in our pytest code.
First, write some failing unit tests of our new helper function:
PYTHON
# test_overlap.py
def test_rotate_rectangle():
rectangle = [1, 2, 3, 3]
rectangle = rotate_rectangle(rectangle)
assert rectangle == [2, -3, 3, -1]
rectangle = rotate_rectangle(rectangle)
assert rectangle == [-3, -3, -1, -2]
rectangle = rotate_rectangle(rectangle)
assert rectangle == [-3, 1, -2, 3]
rectangle = rotate_rectangle(rectangle)
assert rectangle == [1, 2, 3, 3]Writing out the different permutations was challenging (for me, at
least), probably related to having unnamed attributes for our rectangle
as a list of numbers… Then you need to produce the correct rectangle
where x1 <= x2.
PYTHON
# test_overlap.py
def rotate_rectangle(rectangle):
x1, y1, x2, y2 = rectangle
x1, y1 = y1, -x1
x2, y2 = y2, -x2
# make sure x1 <= x2, value = [x1, y1, x2, y2]
x1, x2 = min(x1, x2), max(x1, x2)
y1, y2 = min(y1, y2), max(y1, y2)
return [x1, y1, x2, y2]Notice this is still in our test file. We don’t want it in our project and it’s just a helper for our tests, we could use it elsewhere in later tests. Since the function is non-trivial we also have it tested. For helper functions that mutate or wrap inputs, you could have them non-tested but beware: the simple helper function may eventually evolve into something more complex!
Test the first overlap orientation
Start with the first type of overlap (over corners). Set one
rectangle to (-1, -1, 1, 1) and place the second rectangle.
Transform the second rectangle by rotating it around the origin 3 times
and test the rects_overlap function for each overlap and
red/blue assignment. Hint: pytest code is still python!
With our rotate_rectangle function in hand, the test
function needs to test rects_overlap twice (swapping
arguments each time) then rotate the second rectangle. Note the choice
of centering the first rectangle on the origin makes it rotationally
invariant. Here is a test function, notice that the assert statements
have a clear message as it would otherwise be difficult to tell when a
test failed.
PYTHON
def test_rects_overlap_permutations():
rectangle_1 = [-1, -1, 1, 1]
rectangle_2 = [0, 0, 2, 3]
result = True
for i in range(4):
assert overlap.rects_overlap(rectangle_1, rectangle_2) == result, (
f"Failed rects_overlap({rectangle_1}, {rectangle_2}) "
f"on rotation {i}")
assert overlap.rects_overlap(rectangle_2, rectangle_1) == result, (
f"Failed rects_overlap({rectangle_2}, {rectangle_1}) "
f"on rotation {i}")
rectangle_2 = rotate_rectangle(rectangle_2)I declare the result to simplify parameterize introduced next.
We have test_rects_overlap_permutations written for one
rectangle. You may be tempted to copy and paste the function multiple
times and declare a different rectangle_2 and result for
each orientation we came up with above. To avoid code duplication, you
could make our test a helper function, but pytest has a better builtin
option, parameterize.
pytest.mark.parametrize
Parametrizing a test function allows you to easily repeat its execution with different input values. Using parameters cuts down on duplication and can vastly increase the input space you can explore by nesting parameters.
Let’s work on testing the following function:
Fully testing this function requires testing a variety of
values and ensuring when condition is True the
function instead raises an error. Here are a few tests showing how you
could write multiple test functions:
PYTHON
def test_square_sometimes_number_false():
assert square_sometimes(4, False) == 16
def test_square_sometimes_number_true():
with pytest.raises(ValueError):
square_sometimes(4, True)
def test_square_sometimes_list_false():
assert square_sometimes([1, 1], False) == [1, 1, 1, 1]
def test_square_sometimes_list_true():
with pytest.raises(ValueError):
square_sometimes([1, 1], True)
...Hopefully that code duplication is making your skin crawl! Maybe instead you write a helper function to check the value of condition:
PYTHON
def square_sometimes_test_helper(value, condition, output):
if condition:
with pytest.raises(ValueError):
square_sometimes(value, condition)
else:
assert square_sometimes(value, condition) == outputThen you can replace some of your tests with the helper calls:
PYTHON
def test_square_sometimes_number():
square_sometimes_test_helper(4, False, 16)
square_sometimes_test_helper(4, True, 16)
def test_square_sometimes_list():
square_sometimes_test_helper([1, 1], False, [1, 1, 1, 1])
square_sometimes_test_helper([1, 1], True, [1, 1, 1, 1])
...You could imagine wrapping the helper calls in a loop and you’d
basically have a parametrized test. Using
pytest.mark.parametrize you’d instead have:
PYTHON
@pytest.mark.parametrize(
'value,output',
[
(4, 16),
([1,1], [1,1,1,1]),
('asdf', 'asdfasdf'),
]
)
@pytest.mark.paramterize('condition', [True, False])
def test_square_sometimes(value, condition, output):
if condition:
with pytest.raises(ValueError):
square_sometimes(value, condition)
else:
assert square_sometimes(value, condition) == outputpytest will generate the Cartesian product of all nested parameters, here producing 6 tests. Notice how there is no code duplication and if you come up with another test input, you just have to add it to the ‘value,output’ list; testing each condition will automatically happen. Compared with coding the loops yourself, pytest generates better error reporting on what set of parameters failed. Like most of pytest, there is a lot more we aren’t covering like mixing parameters and fixtures.
Here is the parameterized version of
test_rects_overlap_permutations. We added the unicode
rectangle images because we had already made them above and it seemed
like a shame to not reuse. Normally you wouldn’t spend time making them
and instead use a simple text descriptor, e.g. “Corners overlap”.
PYTHON
rectangle_strs = ['''
┌───┐
│ ┌┼─┐
└──┼┘ │
└──┘''','''
┌──┬──┐
│ │ │
└──┴──┘''','''
┌──────┐
│ ┌──┐ │
└─┼──┼─┘
└──┘''','''
┌─┐
└─┼─┐
└─┘''','''
┌─┐
└─┘ ┌─┐
└─┘''','''
┌──────┐
│ ┌─┐ │
│ └─┘ │
└──────┘''',
]
@pytest.mark.parametrize(
"rectangle_2,rectangle_str,result",
[
([0, 0, 2, 3], rectangle_strs[0], True),
([1, -1, 2, 1], rectangle_strs[1], False),
([0, -2, 0.5, 0], rectangle_strs[2], True),
([1, 1, 2, 2], rectangle_strs[3], False),
([2, 2, 3, 3], rectangle_strs[4], False),
([0, 0, 0.5, 0.5], rectangle_strs[5], True),
])
def test_rects_overlap_permutations(rectangle_2, rectangle_str, result):
rectangle_1 = [-1, -1, 1, 1]
for i in range(4):
assert overlap.rects_overlap(rectangle_1, rectangle_2) == result, (
f"Failed rects_overlap({rectangle_1}, {rectangle_2}) "
f"on rotation {i}. {rectangle_str}")
assert overlap.rects_overlap(rectangle_2, rectangle_1) == result, (
f"Failed rects_overlap({rectangle_2}, {rectangle_1}) "
f"on rotation {i}. {rectangle_str}")
rectangle_2 = rotate_rectangle(rectangle_2)Now failed tests will also show the image along with information to recreate any failures. Running the above should fail… Time to get back to green.
Note that with parameterize, each set of parameters will be run, e.g. failing on the second rectangle will not affect the running on the third rectangle.
Fix the code
Work on the source code for rects_overlap until all the
code passes. Hint: try pytest --pdb test_overlap.py which
launches pdb at the site of the first assertion error.
Only one set of rectangles is failing and it’s on the first rotation. That should indicate our tests are working properly and perhaps there is a more subtle bug hiding in our code. Hopefully it didn’t take too long to see there is a copy paste error in the if statement.
PYTHON
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_x) or (red_hi_y <= blue_lo_y):
# ^ should be y!Notice that all our other tests didn’t exercise this condition. If we weren’t rotating each case we would have also missed this. At least the fix is easy.
In contrast to the last implementation change we made (removing the trailing tab character) this bug fix is more serious. You have revealed an error in code that was previously published!
Were this a real example, you should open an issue with the original code and consider rerunning any dependent analyses to see if results fundamentally change. It may be by chance that branch of code never actually ran and it didn’t matter if it were wrong. Maybe only 1% of cases were miscalled. That would require just a new version to patch the issue. Larger changes in the results may necessitate a revision or retraction of the original publication.
- Testing long methods is difficult since you can’t pinpoint a few lines of logic.
- Testable code is also good code!
- Changing code without tests can be dangerous. Work slowly and carefully making only the simplest changes first.
- Write tests with an adversarial viewpoint.
- Keep tests DRY, fixtures and parameter can help.
Content from Testing Big Changes
Last updated on 2025-07-17 | Edit this page
Overview
Questions
- What does it mean if you have to change a lot of tests while adding features?
- What are the advantages of testing an interface?
Objectives
- Add a
Rectangleclass - Learn how to use TDD when making large changes to code
Making big changes
With this fairly simple example, we have fully tested our codebase. You can rest easy knowing the code is working as well as you’ve tested it. We have made a few changes to what the legacy code used to do and even found a bug. Still, our code functions basically the same as it did (perhaps more correct). How does testing help when we need to add features and really change code?
The answer depends on how well you tested the interface vs the implementation. If your tests are full of duplication, you will have to change a lot of the test code. Now you would want to make a commit of this version of the code and get ready to shake things up. Even if it seems like you are spending a lot of time messing with the tests, at the end once everything passes you should have the same confidence in your code.
Testing the interface vs the implementation
Consider a database object that performs a query and then can return a result as separate function calls. This is not the best design but it is a useful example
PYTHON
class MyDB():
self._result: list
...
def query(self, something):
...
self._result = result
def get_result(self):
return list(self._result)When you call query the result is saved in the
_result attribute of the instance. When you get the result,
a copy is returned as a list.
Consider the following two tests for query:
PYTHON
def test_query_1():
my_db = MyDB()
my_db.query('something')
assert my_db._result == ['a result']
def test_query_2():
my_db = MyDB()
my_db.query('something')
assert my_db.get_result() == ['a result']Currently, they do the same thing. One could argue the first option
is better because it only tests the query function while the second is
also exercising get_result. By convention, the underscore
in front of the attribute in python means it is private and you
shouldn’t really access it. Since “private” is kind of meaningless in
python, a better description is that it is an implementation detail
which could change. Even if it weren’t private, the first test is
testing internal implementation (calling query sets the
result attribute) while the second is testing the interface
(call query first and get_result will give you
the result as a list).
Think about what happens if the _result attribute is
changed from a list to a set, or dictionary. This is valid since no one
should really use _result outside of the class, but in
terms of testing, test_query_1 would break while
test_query_2 still passes, even if the code is
correct. This is annoying because you have to change a lot of test
code but it is also dangerous. Tests that fail for correct code
encourage you to run tests less often and can cause code and tests to
diverge.
Where possible, test to the interface.
Returning a new rectangle
Back to our rectangles, let’s change our rects_overlap
to return a new rectangle when the arguments overlap, and
None when they do not.
Red
We will start with the basic test_rects_overlap
PYTHON
# test_overlap.py
def test_rects_overlap():
rectangles = {
'a': [0, 0, 2, 2],
'b': [1, 1, 3, 3],
'c': [10, 10, 11, 11],
}
assert overlap.rects_overlap(rectangles['a'], rectangles['a']) == [0, 0, 2, 2]
assert overlap.rects_overlap(rectangles['a'], rectangles['b']) == [1, 1, 2, 2]
assert overlap.rects_overlap(rectangles['b'], rectangles['a']) == [1, 1, 2, 2]
assert overlap.rects_overlap(rectangles['a'], rectangles['c']) is NoneWe are failing since the first call returns True instead of our list.
Green
Simple enough, instead of False we should return None and instead of True we need to make a new rectangle with the smaller of the coordinates.
PYTHON
# overlap.py
from typing import Optional
def rects_overlap(red, blue) -> Optional[list[float]]:
red_lo_x, red_lo_y, red_hi_x, red_hi_y = red
blue_lo_x, blue_lo_y, blue_hi_x, blue_hi_y = blue
if (red_lo_x >= blue_hi_x) or (red_hi_x <= blue_lo_x) or \
(red_lo_y >= blue_hi_y) or (red_hi_y <= blue_lo_y):
return None
x1 = max(red_lo_x, blue_lo_x)
x2 = min(red_hi_x, blue_hi_x)
y1 = max(red_lo_y, blue_lo_y)
y2 = min(red_hi_y, blue_hi_y)
return [x1, y1, x2, y2]We are passing the new test_rects_overlap but failing
another 6 tests! That’s because many tests are still testing the old
behavior. If you have kept tests DRY and not tested the implementation,
this should be quick to fix, otherwise take the opportunity to refactor
your tests!
For us, the test_rects_overlap_permutation will accept a
rectangle as the result. On each loop iteration, we need to rotate the
result rectangle. Since None is a valid rectangle now,
rotate_rectangle needs to handle it appropriately. Here is
the finished test method:
PYTHON
@pytest.mark.parametrize(
"rectangle_2,rectangle_str,result",
[
([0, 0, 2, 3], rectangle_strs[0], [0, 0, 1, 1]),
([1, -1, 2, 1], rectangle_strs[1], None),
([0, -2, 0.5, 0], rectangle_strs[2], [0, -1, 0.5, 0]),
([1, 1, 2, 2], rectangle_strs[3], None),
([2, 2, 3, 3], rectangle_strs[4], None),
([0, 0, 0.5, 0.5], rectangle_strs[5], [0, 0, 0.5, 0.5]),
])
def test_rects_overlap_permutations(rectangle_2, rectangle_str, result):
rectangle_1 = [-1, -1, 1, 1]
for i in range(4):
assert overlap.rects_overlap(rectangle_1, rectangle_2) == result, (
f"Failed rects_overlap({rectangle_1}, {rectangle_2}) "
f"on rotation {i}. {rectangle_str}")
assert overlap.rects_overlap(rectangle_2, rectangle_1) == result, (
f"Failed rects_overlap({rectangle_2}, {rectangle_1}) "
f"on rotation {i}. {rectangle_str}")
rectangle_2 = rotate_rectangle(rectangle_2)
result = rotate_rectangle(result)
def rotate_rectangle(rectangle):
if rectangle is None:
return None
x1, y1, x2, y2 = rectangle
x1, y1 = y1, -x1
x2, y2 = y2, -x2
# make sure x1 <= x2, value = [x1, y1, x2, y2]
x1, x2 = min(x1, x2), max(x1, x2)
y1, y2 = min(y1, y2), max(y1, y2)
return [x1, y1, x2, y2]Refactor
Since our tests are fairly small and not too coupled to the implementation we don’t have to change anything. If you had written the permutation function as 48 separate tests, it would make sense to refactor that while updating the return values!
End-to-end test?
You may be surprised our end to end test is still passing. This is a feature of python more than any design of our system. The line
works properly because None evaluates as False while a
non-empty list evaluates as True in a boolean context.
Take a minute to reflect on this change. Creating a new rectangle is non-trivial, it would be easy to mix up a min or max or introduce a copy/paste error. Since we have tests, we can be confident we made this change correctly. With our end-to-end test we further know that our main method is behaving exactly the same as well.
A Rectangle Object
Any decent OOP developer would be pulling their hair over using a list of 4 numbers as a rectangle when you could have a full object hierarchy! We have another design decision before we really dig into the changes, how much should we support the old format of a rectangle as a list of numbers? Coming from strict, static typing you may be inclined to say “not at all” but python gains power from its duck typing.
Consider adding support for comparing a rectangle to a list of
numbers. If you support lists fully we can maintain the same tests.
However, a user may not expect a list to equal a rectangle and could
cause problems with other code. Since we want to focus on writing tests
instead of advanced python we will try to replace everything with
rectangles. In real applications you may want to transiently add support
for comparisons to lists so the tests pass to confirm any other logic is
sound. After the tests are converted to rectangles you would alter your
__eq__ method to only compare with other rectangles.
Without getting carried away, we want our rectangles to support -
Construction from a list of numbers or with named arguments - Comparison
with other rectangles, primarily for testing - Calculation of area - An
overlap function with a signature like
def overlap(self, other: Rectangle) -> Rectangle.
Afterwards, our main loop code will change from
PYTHON
result = '1' if rects_overlap(red_coords, blue_coords) else '0'
# to
overlap_area = red_rectangle.overlap(blue_rectangle).area()We will also need to change code in our read_rectangles
and rects_overlap functions as well as
main.
Order of Operations
Should we start with converting our existing tests or making new tests for the rectangle object?
It’s better to work from bottom up, e.g. test creating a rectangle
before touching read_rectangles.
Imaging a red, green, refactor cycle where you start with updating
read_rectangles to return a (yet unimplemented) Rectangle
object. First change your tests to expect a Rectangle to get them
failing. The problem is to get them passing you need to add code to
create a rectangle and test for equality. It’s possible but then you
don’t have unit tests for those functions. Furthermore, that breaks with
the idea that TDD cycles should be short; you have to add a lot of code
to get things passing!
TDD: Creating Rectangles
Starting with a new test, we will simply check that a new rectangle can be created from named arguments.
PYTHON
# test_overlap.py
def test_create_rectangle_named_parameters():
assert overlap.Rectangle(x1=1.1, x2=2, y1=4, y2=3)Fails because there is no Rectangle object yet. To get green, we are going to use a python dataclass:
PYTHON
# overlap.py
from dataclasses import dataclass
@dataclass
class Rectangle:
x1: float
y1: float
x2: float
y2: floatThe dataclass produces a default __init__
and __eq__.
How about rectangles from lists?
PYTHON
# test_overlap.py
def test_create_rectangle_from_list():
assert overlap.Rectangle.from_list([1.1, 4, 2, 3])Here we are using the order of parameters matching the existing implementation. The code uses a bit of advanced python but should be clear:
PYTHON
# overlap.py
class Rectangle:
# ...
@classmethod
def from_list(cls, coordinates: list[float]):
x1, y1, x2, y2 = coordinates
return cls(x1=x1, y1=y1, x2=x2, y2=y2)And let’s add a test for the incorrect number of values in the list:
PYTHON
# test_overlap.py
def test_create_rectangle_from_list_wrong_number_of_args():
with pytest.raises(ValueError) as error:
overlap.Rectangle.from_list([1.1, 4, 2])
assert "Incorrect number of coordinates " in str(error)
with pytest.raises(ValueError) as error:
overlap.Rectangle.from_list([1.1, 4, 2, 2, 2])
assert "Incorrect number of coordinates " in str(error)And update the code.
PYTHON
# overlap.py
class Rectangle:
# ...
@classmethod
def from_list(cls, coordinates: list[float]):
if len(coordinates) != 4:
raise ValueError(f"Incorrect number of coordinates for '{coordinates}'")
x1, y1, x2, y2 = coordinates
return cls(x1=x1, y1=y1, x2=x2, y2=y2)Notice that we now have some code duplication since we use the same
check in read_rectangles. But we can’t remove it until we
start using the Rectangle there.
TDD: Testing equality
Instead of checking our rectangles are just not None, let’s see if they are what we expect:
PYTHON
# test_overlap.py
def test_create_rectangle_named_parameters():
assert overlap.Rectangle(1.1, 4, 2, 3) == overlap.Rectangle(1.1, 3, 2, 4)
assert overlap.Rectangle(x1=1.1, x2=2, y1=4, y2=3) == overlap.Rectangle(1.1, 3, 2, 4)
def test_create_rectangle_from_list():
assert overlap.Rectangle.from_list([1.1, 4, 2, 3]) == overlap.Rectangle(1.1, 3, 2, 4)Here we use unnamed parameters during initialization to check for
equality. The order of attributes in the dataclass determines the order
of assignment. Since that’s fairly brittle, consider adding
kw_only for production code.
This fails not because of an issue with __eq__ but the
__init__, we aren’t ensuring our expected ordering of
x1 <= x2. You could overwrite __init__ but
instead we will use a __post_init__ to valid the
attributes.
PYTHON
# overlap.py
@dataclass
class Rectangle:
x1: float
y1: float
x2: float
y2: float
def __post_init__(self):
self.x1, self.x2 = min(self.x1, self.x2), max(self.x1, self.x2)
self.y1, self.y2 = min(self.y1, self.y2), max(self.y1, self.y2)Note this also fixes the issue with from_list as it
calls __init__ as well. If we later decide to add an
attribute like color the __init__ method would
update and our __post_init__ would function as
intended.
TDD: Calculate Area
For area we can come up with a few simple tests:
PYTHON
# test_overlap.py
def test_rectangle_area():
assert overlap.Rectangle(0, 0, 1, 1).area() == 1
assert overlap.Rectangle(0, 0, 1, 2).area() == 2
assert overlap.Rectangle(0, 1, 2, 2).area() == 2
assert overlap.Rectangle(0, 0, 0, 0).area() == 0
assert overlap.Rectangle(0, 0, 0.3, 0.3).area() == 0.09
assert overlap.Rectangle(0.1, 0, 0.4, 0.3).area() == 0.09The code shouldn’t be too surprising:
PYTHON
# overlap.py
@dataclass
class Rectangle:
...
def area(self):
return (self.x2-self.x1) * (self.y2-self.y1)But you may be surprised that the last assert is failing, even though the second to last is passing. Again we are struck by the limits of floating point precision.
Fix the tests
Fix the issue of floating point comparison. Hint, look up
pytest.approx.
TDD: Overlap
Now we have the challenge of replacing the rects_overlap
function with a Rectangle method with the following signature
def overlap(self, other: Rectangle) -> Rectangle.
Red, green, refactor
Perform an iteration of TDD to add the overlap method to
Rectangle. Hint, start with only the
test_rects_overlap test for now.
Red
PYTHON
# test_overlap.py
def test_rectangle_overlap():
rectangles = {
'a': overlap.Rectangle(0, 0, 2, 2),
'b': overlap.Rectangle(1, 1, 3, 3),
'c': overlap.Rectangle(10, 10, 11, 11),
}
assert rectangles['a'].overlap(rectangles['a']) == overlap.Rectangle(0, 0, 2, 2)
assert rectangles['a'].overlap(rectangles['b']) == overlap.Rectangle(1, 1, 2, 2)
assert rectangles['b'].overlap(rectangles['a']) == overlap.Rectangle(1, 1, 2, 2)
assert rectangles['a'].overlap(rectangles['c']) is NoneGreen
You can copy most of the current code to the new method with changes to variable names.
PYTHON
# overlap.py
class Rectangle:
...
def overlap(self, other):
if (self.x1 >= other.x2) or \
(self.x2 <= other.x1) or \
(self.y1 >= other.y2) or \
(self.y2 <= other.y1):
return None
return Rectangle(
x1=max(self.x1, other.x1),
y1=max(self.y1, other.y1),
x2=min(self.x2, other.x2),
y2=min(self.y2, other.y2),
)This was after refactoring to get rid of extra variables. Since we
can use named arguments for new rectangles, we don’t have to set
x1 separately for clarity. ### Refactor While it’s tempting
to go forth and replace all rects_overlap calls now, we
need to work on some other tests first.
Wrapping up the overlap tests, we need to work on
rotate_rectangle and the overlap permutations function. I
think it makes sense to move our rotate function to
Rectangle now. While we don’t use it in our main method,
the class is becoming general enough to be used outside our current
script.
PYTHON
# test_overlap.py
def test_rotate_rectangle():
rectangle = overlap.Rectangle(1, 2, 3, 3)
rectangle = rectangle.rotate()
assert rectangle == overlap.Rectangle(2, -3, 3, -1)
rectangle = rectangle.rotate()
assert rectangle == overlap.Rectangle(-3, -3, -1, -2)
rectangle = rectangle.rotate()
assert rectangle == overlap.Rectangle(-3, 1, -2, 3)
rectangle = rectangle.rotate()
assert rectangle == overlap.Rectangle(1, 2, 3, 3)The special case when Rectangle is None is not handled
anymore since you can’t call the method rotate on a None
object.
PYTHON
# overlap.py
class Rectangle:
...
def rotate(self):
return Rectangle(
x1=self.y1,
y1=-self.x1,
x2=self.y2,
y2=-self.x2,
)That is much cleaner than the last version. Now to handle
our None rectangles, we will keep our
rotate_rectangle helper function in the test code to wrap
our method dispatch and modify our test:
PYTHON
# test_overlap.py
def rotate_rectangle(rectangle):
if rectangle is None:
return None
return rectangle.rotate()
...
@pytest.mark.parametrize(
"rectangle_2,rectangle_str,result",
[
(overlap.Rectangle(0, 0, 2, 3), rectangle_strs[0], overlap.Rectangle(0, 0, 1, 1)),
(overlap.Rectangle(1, -1, 2, 1), rectangle_strs[1], None),
(overlap.Rectangle(0, -2, 0.5, 0), rectangle_strs[2], overlap.Rectangle(0, -1, 0.5, 0)),
(overlap.Rectangle(1, 1, 2, 2), rectangle_strs[3], None),
(overlap.Rectangle(2, 2, 3, 3), rectangle_strs[4], None),
(overlap.Rectangle(0, 0, 0.5, 0.5), rectangle_strs[5], overlap.Rectangle(0, 0, 0.5, 0.5)),
])
def test_rectangles_overlap_permutations(rectangle_2, rectangle_str, result):
rectangle_1 = overlap.Rectangle(-1, -1, 1, 1)
for i in range(4):
assert rectangle_1.overlap(rectangle_2) == result, (
f"Failed {rectangle_1}.overlap({rectangle_2}) "
f"on rotation {i}. {rectangle_str}")
assert rectangle_2.overlap(rectangle_1) == result, (
f"Failed {rectangle_2}.overlap({rectangle_1}) "
f"on rotation {i}. {rectangle_str}")
rectangle_2 = rotate_rectangle(rectangle_2)
result = rotate_rectangle(result)And we can almost get rid of rects_overlap entirely.
It’s not in our tests, but we do use it in our main script. The last
function to change is read_rectangles.
TDD: Read rectangles
Red, green, refactor
Perform an iteration of TDD to make the read_rectangles
function return Rectangles.
Green(ish)
The original code dealing with coordinate ordering and number of
coordinates can be removed as that’s now handled by
Rectangle.
PYTHON
# overlap.py
def read_rectangles(rectangles: Iterable[str]) -> dict[str, Rectangle]:
result = {}
for rectangle in rectangles:
name, *coords = rectangle.split()
try:
value = [float(c) for c in coords]
except ValueError:
raise ValueError(f"Non numeric value provided as input for '{rectangle}'")
result[name] = Rectangle.from_list(value)
return resultThis is not a real green since other tests are failing, but at least
test_read_rectangles_simple is passing. ### Refactor You
have to touch a lot of test code to get everything passing. Also you
need to modify the main method. Afterwards you can finally remove
rects_overlap.
TDD: Area of overlap
Recall we set out to do all this in order to output the area of the
overlap of a rectangle, instead of just 1 when rectangles
overlap. That change will only affect our end to end test. It may be
prudent to extract the line
into a separate function to exercise it more fully, but for now we will leave it.
Red, green, refactor
Perform an iteration of TDD to make the main function
output the area of overlap.
Red
Our simple rectangles aren’t the best for testing, but we are at
least confident our area method is well tested
elsewhere.
PYTHON
# test_overlap.py
def test_end_to_end(simple_input):
# initialize a StringIO with a string to read from
infile = simple_input
# this holds our output
outfile = StringIO()
# call the function
overlap.main(infile, outfile)
output = outfile.getvalue().split('\n')
assert output[0] == '4.0\t1.0\t0'
assert output[1] == '1.0\t4.0\t0'
assert output[2] == '0\t0\t1.0'Green
PYTHON
# overlap.py
def main(infile, outfile):
rectangles = read_rectangles(infile)
for red_name, red_rect in rectangles.items():
output_line = []
for blue_name, blue_rect in rectangles.items():
overlap = red_rect.overlap(blue_rect)
result = str(overlap.area()) if overlap else '0'
output_line.append(result)
outfile.write('\t'.join(output_line) + '\n')Big Conclusions
Take a breath, we are out of the deep end of rectangles for now. At this point, you may think TDD has slowed you down; sometimes a simple change of code required touching a lot of test code just to have the same performance and functionality. If that’s your impression, consider the following: - Make new mistakes. Nothing is worse than finding the same bug twice. It is hard to appreciate preventing regressions on simple problems like we used here, but the overlap and rotate functions are close. Once you’ve put in the time to write a test and are confident in the results, it is easier to make changes touching that code because the previous tests should still pass. Without tests you may forget a negative sign or make a typo when refactoring and not notice until production. Don’t spend your time making the same mistakes, go forth and make new mistakes! - Go far, not fast. There is a proverb “If you want to go fast, go alone. If you want to go far, go together.” The translation to testing breaks down because frequently having tests makes your work go much faster. You are investing in code upfront with tests to limit debugging time later. - Work with a safety net. Moving to a problem of larger complexity, working on legacy code can feel unsettling. The entire system is too large and opaque to be sure everything works so you are left with an uneasy feeling that maybe a change you made introduced a bug. With tests, you can sleep soundly knowing all your tests passed. There may be bugs, but they are new bugs.
As you move into open source projects or work with multiple collaborators, fully tested codebases make sure the quality of the project won’t degrade as long as tests are informative, fast, and fun to write.
- Changing a lot of test code for minor features can indicate your tests are not DRY and heavily coupled.
- Testing a module’s interface focuses tests on what a user would typically observe. You don’t have to change as many tests when internal change.